Speechma
Converts text into high-quality, natural-sounding audio for videos, podcasts, and social media content.
Are you the owner?
Claim this tool to publish updates, news and respond to users.
Sign in to claim ownership
Sign InDescription
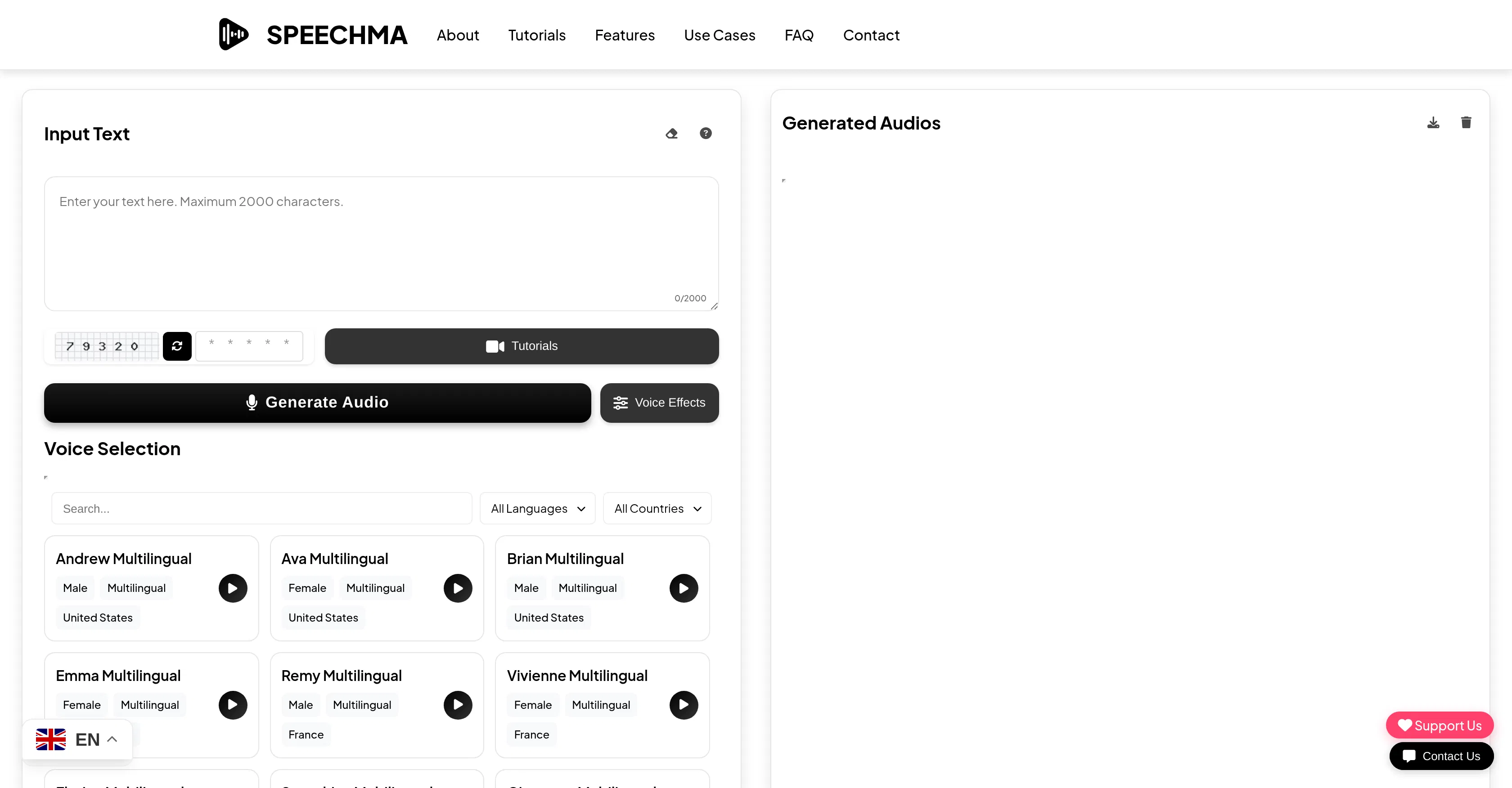
Speechma is an advanced text-to-speech conversion tool developed by ElevenLabs, designed to provide professional-grade audio synthesis for a wide range of personal and commercial applications. Its core value lies in democratizing access to high-fidelity, natural-sounding voiceovers, eliminating the need for expensive recording equipment or professional voice actors. The platform is built with a focus on ease of use, allowing creators of all skill levels to quickly generate audio content that enhances their digital projects.
Key features include the ability to generate speech in multiple languages and accents, fine-tune voice parameters like stability and clarity, and clone voices from short audio samples. Users can adjust speech rate, pitch, and pauses for dramatic effect, and the tool supports batch processing for converting large volumes of text efficiently. The output is delivered in high-quality audio formats suitable for professional editing and direct publishing.
What sets Speechma apart is its underlying AI model, which is specifically engineered to capture the nuances of human speech, including intonation and emotional inflection, resulting in remarkably lifelike audio. It operates as a web-based platform with a clean, intuitive interface, requiring no software installation. While it integrates seamlessly into content creation workflows for platforms like YouTube and TikTok, it also offers API access for developers looking to embed its capabilities into custom applications or services.
Ideal for video producers, podcasters, social media marketers, and educators who need to create engaging audio content quickly and cost-effectively. Specific use cases include generating voiceovers for explainer videos, creating audio versions of blog posts or articles, producing character voices for games or animations, and localizing content for international audiences by generating speech in different languages.